Assessment |
Biopsychology |
Comparative |
Cognitive |
Developmental |
Language |
Individual differences |
Personality |
Philosophy |
Social |
Methods |
Statistics |
Clinical |
Educational |
Industrial |
Professional items |
World psychology |
Biological: Behavioural genetics · Evolutionary psychology · Neuroanatomy · Neurochemistry · Neuroendocrinology · Neuroscience · Psychoneuroimmunology · Physiological Psychology · Psychopharmacology (Index, Outline)

{kind=link}
Pacific Northwest National Laboratory's high magnetic field (800 MHz) NMR spectrometer being loaded with a sample.
Protein nuclear magnetic resonance spectroscopy, abbreviated protein NMR is a field of structural biology, that applies nuclear magnetic resonance spectroscopy to investigating proteins. The goal is to obtain information about the structure and dynamics of the proteins under investigation. The field was pioneered by, among others, Kurt Wüthrich, who won the Nobel prize in 2002, and is being continually used and improved in both academia and the biotech industry. Structure determination by nuclear magnetic resonance spectroscopy usually consists of several following phases, each using a separate set of highly specialized techniques. The sample is prepared, resonances are assigned, restraints are generated and a structure is calculated and validated.
Sample preparation[]

{kind=link}
The NMR sample is prepared in a thin walled glass tube.
Protein nuclear magnetic resonance is performed on aqueous samples of highly purified protein. Usually the sample consist of between 300 and 600 microlitres with a protein concentration in the range 0.1 – 3 millimolar. The source of the protein can be either natural or produced in an expression system using recombinant DNA techniques through genetic engineering. Recombinantly expressed proteins are usually easier to produce in sufficient quantity, and makes isotopic labelling possible.
The most abundant isotopes of carbon and oxygen, carbon-12 and oxygen-16, have no net nuclear spin, which is the physical property nuclear magnetic resonance spectroscopy exploits. The most abundant isotopes of nitrogen, nitrogen-14, has a net nuclear spin; however, it also has a large quadrupolar moment, a property of the atomic nuclei which prevents high-resolution information to be obtained from this isotope. Thus nuclear magnetic resonance of proteins from natural sources are restricted to utilizing nuclear magnetic resonance based solely on protons. However the less common isotopes, carbon-13 and nitrogen-15, are suitable for nuclear magnetic resonance, and therefore labelling the proteins with these compounds open up possibilities for doing more advanced experiments which also detect or use these nuclei. Isotopical labelling is done by growing the expression host on a growth media enriched in the desired isotopes. Since isotopically enriched compounds remain expensive, organisms are used which are capable of growing on a defined minimal medium, containing only one carbon-13 source, usually glucose, but occasionally glycerol or methanol, and one nitrogen-15 source such as ammonium chloride or ammonium sulfate . These organisms include bacteria such as Escherichia coli, which is is the most frequently used and unicellular fungi.
The purified protein is usually dissolved in a buffer and adjusted to the desired solvent conditions.
Data collection[]
Protein NMR utilizes multidimensional nuclear magnetic resonance experiments to obtain information about the protein. Ideally, each distinct nucleus in the molecule experiences a distinct chemical environment and thus has a distinct chemical shift by which it can be recognized. However in large molecules such as proteins the number of resonances can typically be several thousand and a one-dimensional spectrum inevitably has accidental overlaps. Therefore multidimensional experiments are performed which correlate the frequencies of distinct nuclei. The additional dimensions decrease the chance of overlap and have a larger information content since they correlate signals from nuclei within a specific part of the molecule. Magnetization is transferred between nuclei using radiofrequency pulses and delays via one of many elaborate pulse sequences which allow connections between different nuclei to be detected. The array of nuclear magnetic resonance experiments used on proteins fall in two main categories — one where magnetization is transferred through the chemical bonds, and one where the transfer is through space, irrespective of the bonding structure. The first category is used to assign the different chemical shifts to a specific nucleus, and the second is primarily used to generate the distance restraints used in the structure calculation, and in the assignment with unlabelled protein.
Depending on the concentration of the sample, on the magnetic field of the spectrometer, and on the type of experiment, a single multidimensional nuclear magnetic resonance experiment on a protein sample may take hours or even several days to obtain suitable signal-to-noise ratio through signal averaging, and to allow for sufficient evolution of magnetization transfer through the various dimensions of the experiment. Other things being equal, higher-dimensional experiments will take longer than lower-dimensional experiments.
Typically the first experiment to be measured with an isotope-labelled protein is a 2D heteronuclear single quantum correlation (HSQC) spectrum where "heteronuclear" refers to nuclei other than 1H. In theory the heteronuclear single quantum correlation has one peak for each H bound to a heteronucleus. Thus in the 15N-HSQC one signal is expected for each amino acid residue along with some additional signals for certain N-containing sidechains such as Tryptophan. The 15N-HSQC is often referred to as the fingerprint of a protein because each protein has a unique pattern of signal positions. Analysis of the 15N-HSQC allows researchers to evaluate whether the expected number of peaks is present and thus to identify possible problems due to multiple conformations or sample heterogeneity. The relatively quick heteronuclear single quantum correlation experiment helps determine the feasibility of doing subsequent longer, more expensive, and more elaborate experiments. It is not possible to assign peaks to specific atoms from the heteronuclear single quantum correlation alone.
Resonance assignment[]
In order to analyze the nuclear magnetic resonance data, it is important to get a resonance assignment for the protein. That is to find out which chemical shift in each dimension corresponds to which atom. Several different types of experiments have been invented to achieve this. The procedure depends on whether the protein is isotopically labelled or not, since a lot of the assignment experiments depend on carbon-13 and nitrogen-15.

{kind=link}
Comparison of a COSY and TOCSY 2D spectra for an amino acid like glutamate or methionine. The TOCSY shows off diagonal crosspeaks between all protons in the spectrum, but the COSY only has crosspeaks between neighbours.
Homonuclear nuclear magnetic resonance[]
With unlabelled protein the usual procedure is to record a set of two dimensional homonuclear nuclear magnetic resonance experiments through correlation spectroscopy (COSY), of which several types include conventional correlation spectroscopy, total correlation spectroscopy (TOCSY) and nuclear Overhauser effect spectroscopy (NOESY)[1]. A two-dimensional nuclear magnetic resonance experiment produces a two-dimensional spectrum. The unit of the both axis are chemical shift. The cosy and tocsy transfer magnetization through the chemical bonds between adjacant protons. The conventional correlation spectroscopy experiment is only able to transfer magnetization between protons on adjacent atoms, whereas in the total correlation spectroscopy experiment the protons are able to relay the magnetization, so it is transferred among all the protons that are connected by adjacent protons. Thus in a conventional correlation spectroscopy, an alpha proton transfers magnetization to the beta protons, the beta protons transfers to the alpha and gamma protons, if any are present, then the gamma proton transfers to the beta and the delta protons, and the process continues. In total correlation spectroscopy, the alpha and all the other protons are able to transfer magnetization to the beta, gamma, delta, epsilon if they are connected by a continuous chain of protons. The continuous chain of protons are the sidechain of the individual amino acids. Thus these two experiments are used to build so called spin systems, that is build a list of resonances of the chemical shift of the peptide proton, the alpha protons and all the protons from each residue’s sidechain. Which chemical shifts corresponds to which nuclei in the spin system is determined by the conventional correlation spectroscopy connectivities and the fact that different types of protons have characteristic chemical shifts. To connect the different spinsystems in a sequential order, the nuclear Overhauser effect spectroscopy experiment have to be used. Because this experiment transfers magnetization through space, it will show crosspeaks to all protons that are close in space regardless of whether they are in the same spin system or not. The neighbouring residues are inherently close in space, so the assignments can be made by the peaks in the NOESY with other spin systems.
One important problem using homonuclear nuclear magnetic resonance is overlap between peaks. That is different protons having the same or very similar chemical shifts. This problem becomes greater as the protein becomes greater, so homonuclear nuclear magnetic resonance is usually restricted to small proteins or peptides.
Nitrogen-15 nuclear magnetic resonance[]
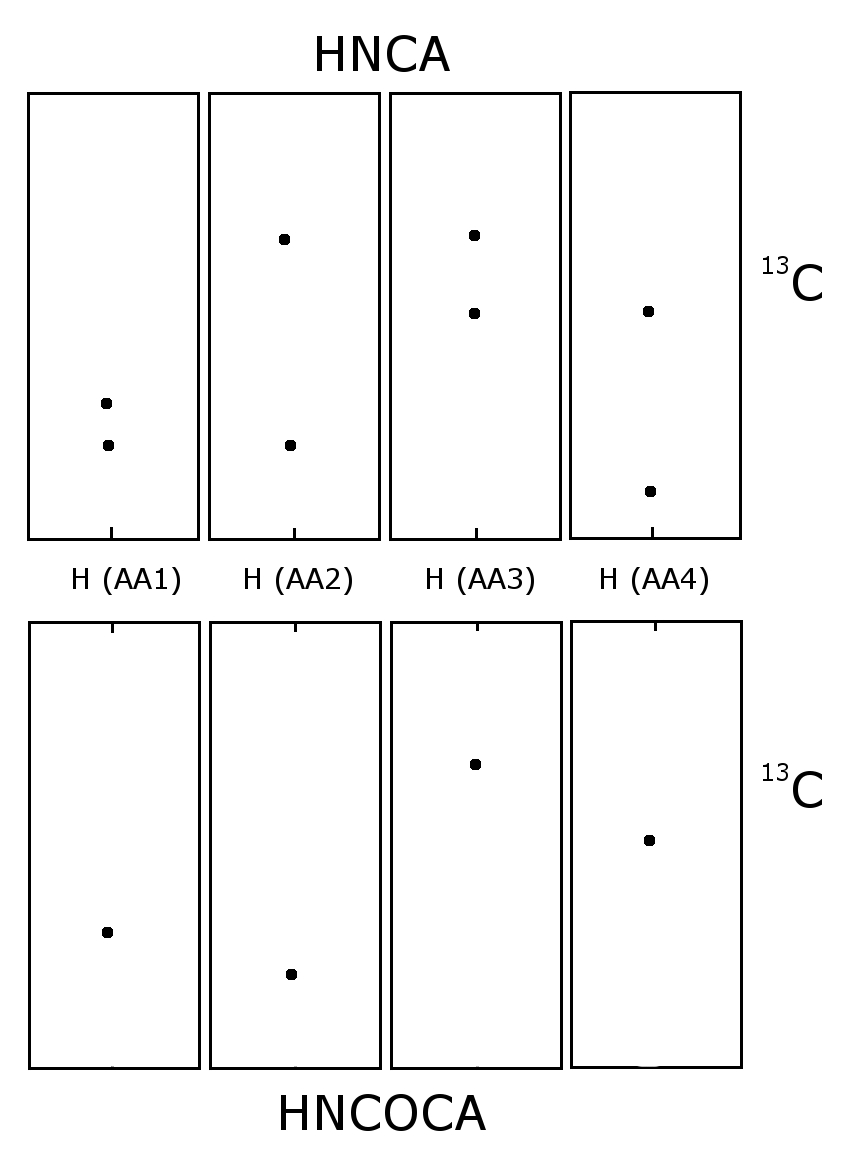
{kind=link}
Schematic of an HNCA and HNCOCA for four sequential residues. The nitrogen-15 dimension is perpendicular to the screen. Each window is focused on the nitrogen chemical shift of that amino acid. The sequential assignment is made by matching the alpha carbon chemical shifts. In the HNCA each residue sees the alpha carbon of it self and the preceding residue. The HNCOCA only sees the alpha carbon of the preceding residue.
The process of resonance assignment for a nitrogen-15 labelled sample is similar to the homonuclear case. No experiment can be performed that transfers magnetisation between two spin systems through bonds either. The main difference is the ability to record nitrogen-15 edited three dimensional experiments: TOCSY-N HSQC and NOESY-N-HSQC. These experiments build onto the HSQC experiment, but have an additional proton dimension. It can be visualised as each peak in the HSQC having the TOCSY or NOESY peaks stacked onto it. Thus if the TOCSY peak from an amide proton, HN, has a cross peak to its alpha proton, Halpha, at the coordinates (HN, Halpha) in the TOCSY spectrum, the corresponding peak would be at (HN, Halpha,N) in the TOCSY-N-HSQC. Thus it is possible to resolve overlaps in the proton dimension, if the corresponding nitrogens have chemical shifts distinct from one another.
Carbon-13 and nitrogen-15 nuclear magnetic resonance[]
When the protein is labelled with carbon-13 and nitrogen-15 it is possible to record an experiment that transfers magnetisation over the peptide bond, and thus connect different spin systems through bonds. This is usually done using some of the following experiments, HNCO, HNCACO, HNCA[2], HNCOCA, HNCACB and CBCACONH. All six experiments consist of a HSQC plane expanded with a carbon dimension. In the HNCO the spectrum contains peaks at the chemical shifts of the carbonyl carbons in the residue of the HSQC peak and the previous one in the sequence. The HNCACO only contains the one from the previous residue, and it is thus possible to assign the carbonyl carbon shifts that corresponds to each HSQC peak and the one previous to that one. Thus it is possible to make the assignment by matching the shifts of each spin system's own and previous carbons. The HNCA and HNCOCA works similarly, just with the alpha carbons rather than the carbonyls, and the HNCACB and the CBCACONH contains both the alpha carbon and the beta carbon. Usually several of these experiments are required to resolve overlap in the carbon dimension. This procedure is usually less ambiguous than the noesy based method, since it is based on through bond transfer. In the NOESY-based methods additional peaks that are close in space but not belonging to the sequential residues will appear confusing the assignment process. When the sequential assignment has been made it is usually possible to assign the sidechains using HCCH-TOCSY, which is basically a TOCSY experiment resolved in an additional carbon dimension.
Restraint generation[]
In order to make structure calculations a number of experimentially determined restraints have to be generated. These fall into different categories, the most widely used is distance restraints and angle restraints.
Distance restraints[]
A crosspeak in a NOESY experiment signifies spatial proximity between the two nuclei in question. Thus each peak can be converted in to a maximum distance between the nuclei, usually between 1,8 and 6 angstroms. The intensity of a noesy peak is proportional to the distance to the minus 6th power, so the distance is determined according to intensity of the peak. The intensity-distance relationship is not exact, so usually a distance range is used.
It is of great importance to assign the noesy peaks to the correct nuclei based on the chemical shifts. If this task is performed manually it is usually very labor intensive, since proteins usually have thousands of noesy peaks. Some computer programs such as CYANA[3] perform this task automatically, coupled to a structure calculation.
To obtain as accurate assignments as possible it is a great advantage to have access to carbon-13 and nitrogen-15 noesy experiments, since they help to resolve overlap in the proton dimension. This leads to faster and more reliable assignments, and in turn to better structures.
Angle restraints[]
In addition to distance restraints, restraints on the torsion angles of the chemical bonds, typically the psi and phi angles can be generated. One approach is to use the Karplus equation, to generate angle restraints from coupling constants. Another approach uses the chemical shifts to generate angle restraints. Both methods use the fact that the geometry around the alpha carbon affects the coupling constants and chemical shifts, so given the coupling constants or the chemical shifts, a qualified guess can be made about the torsion angles.
Orientation restraints[]
The analyte molecules in a sample can be partially ordered with respect to the external magnetic field of the spectrometer by manipulating the sample conditions. Common techniques include addition of bacteriophages or bicelles to the sample, or preparation of the sample in a stretched polyacrylamide gel. This creates a local environment that favours certain orientations of nonspherical molecules. Normally in solution NMR the dipolar coupling between nuclei are averaged out because of the fast tumbling of the molecule. The slight overpopulation one orientation means that a residual dipolar coupling remains to be observed. The dipolar coupling is commonly used in solid state NMR and provides information about the relative orientation of the bond vectors relative to a single global reference frame. Typically the orientation of the N-H vector is probed in a HSQC like experiment. Initially residual dipolar couplings were used for refinement of previously determined structures, but attempts at de novo structure determination have also been made. [4]

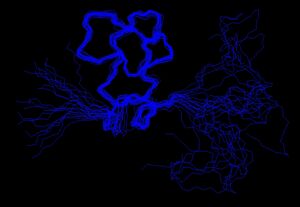
{kind=link}
Nuclear magnetic resonance structure determination generates an ensemble of structures. The structures will only converge if the data is sufficient to dictate a specific fold. In these structures, it is only the case for a part of the structure. From PDB 1SSU.
Hydrogen-Deuterium exchange[]
- Main article: Hydrogen-deuterium exchange
NMR spectroscopy is nuclei specific. Thus it can distinguish between hydrogen and deuterium. The amide protons in the protein exchange readily with the solvent, and if the solvent contains a different isotope, typically deuterium, the reaction can by monitored by NMR spectroscopy. How rapidly a given amide exchanges reflects how exposed it is to the solvent. Thus amide exchange rates can give information on which parts of the protein are buried, hydrogen bonded etc. A common application is to compare the exchange of a free form versus a complex. The amides that become protected in the complex, are assumed to be in the interaction interface.
Structure calculation[]
The experimentially determined restraints can be used as input for the structure calculation process. Researchers, using computer programs such as CYANA or XPLOR-NIH[5], attempt to satisfy as many of the restraints as possible, in addition to general properties of proteins such as bond lengths and angles. The algorithms convert the restraints and the general protein properties into energy terms, and thus tries to minimize the energy. The process results in an ensemble of structures that, if the data were sufficient to dictate a certain fold, will converge.
Dynamics[]
In addition to structures, nuclear magnetic resonance can yield information on the dynamics of various parts of the protein. This usually involves measuring relaxation times such as T1 and T2 to determine order parameters, correlation times, and chemical exchange rates. NMR relaxation is a consequence of local fluctuating magnetic fields within a molecule. Local fluctuating magnetic fields are generated by molecular motions. In this way measurements of relaxation times can provide information of motions within a molecule on the atomic level. In NMR studies of protein dynamics the nitrogen-15 isotope is the preferred nucleus to study, because its relaxation times are relatively simple to relate to molecular motions, which however requires isotope labeling of the protein. The T1 and T2 relaxation times can be measured using various types of HSQC based experiments. The types of motions, which can be detected, are motions that occur on a time-scale ranging from about 10 picoseconds to about 10 nanosecond. In addition slower motions, which take place on a time-scale ranging from about 10 microseconds to 100 milliseconds can also be studied. However since nitrogen atoms are mainly found in the backbone of a protein, the results mainly reflect the motions of the backbone, which is the most rigid part of a protein molecule. Thus, the results obtained from nitrogen-15 relaxation measurements may not be representative for the whole protein. Therefore techniques utilizing relaxation measurements of carbon-13 and deuterium have recently been developed, which enables systematic studies of motions of the amino acid side chains in proteins.
NMR spectroscopy on large proteins[]
Traditionally nuclear magnetic resonance spectroscopy has been limited to relatively small proteins or protein domains. This is in part caused by problems resolving overlapping peaks in larger proteins, but this has been alleviated by the introduction of isotope labelling and multidimensional experiments. Another more serious problem is the fact that in large proteins the magnetization relaxes faster, which means there is less time to detect the signal. This in turn causes the peaks to become broader and weaker, and eventually disappear. Two techniques have been introduced to attenuate the relaxation: transverse relaxation-optimized spectroscopy (TROSY) [6] and deuteration [7] of proteins. By using these techniques it has been possible to study proteins in complex with the 900 kDa chaperone GroES-GroEL [8].
Automatization of the process[]
Structure determination by NMR has traditionally been a time consuming process, requiring interactive analysis of the data by a trained scientist. There has been a considerable interest in automatizing the process to increase the throughput of structure determination (See structural genomics). The two most time consuming processes are the resonance assignment and the NOE assignment. Several different computer programs have been published that do this processes automatically [9][10]. Efforts have also been made to standardize the structure calculation protocol to make it quicker and more amenable to automation[11].
See also[]
References[]
Citations[]
- ^ Protein structure determination in solution by NMR spectroscopy Wuthrich K. J Biol Chem. 1990 Dec 25;265(36):22059-62
- ^ Automated NMR structure calculation with CYANA. Guntert P. Methods Mol Biol. 2004;278:353-78.
- ^ An efficient 3D NMR technique for correlating the proton and 15N backbone amide resonances with the alpha-carbon of the preceding residue in uniformly 15N/13C enriched proteins. Bax A, Ikura M. J Biomol NMR. 1991 May;1(1):99-104.
- ^ Residual dipolar couplings in protein structure determination. de Alba E, Tjandra N. Methods Mol Biol. 2004;278:89-106
- ^ The Xplor-NIH NMR molecular structure determination package. Schwieters CD, Kuszewski JJ, Tjandra N, Clore GM. J Magn Reson. 2003 Jan;160(1):65-73
- ^ Attenuated T2 relaxation by mutual cancellation of dipole-dipole coupling and chemical shift anisotropy indicates an avenue to NMR structures of very large biological macromolecules in solution. Pervushin K, Riek R, Wider G, Wuthrich K. Proc Natl Acad Sci U S A. 1997 Nov 11;94(23):12366-71.
- ^ Effect of deuteration on the amide proton relaxation rates in proteins. Heteronuclear NMR experiments on villin 14T. Markus MA, Dayie KT, Matsudaira P, Wagner G. J Magn Reson B. 1994 Oct;105(2):192-5
- ^ NMR analysis of a 900K GroEL GroES complex. Fiaux J, Bertelsen EB, Horwich AL, Wuthrich K. Nature. 2002 Jul 11;418(6894):207-11.
- Guntert, P. See above
- ^ ARIA: automated NOE assignment and NMR structure calculation. Linge JP, Habeck M, Rieping W, Nilges M. Bioinformatics. 2003 Jan 22;19(2):315-6.
- ^ NMR data collection and analysis protocol for high-throughput protein structure determination. Liu G, Shen Y, Atreya HS, Parish D, Shao Y, Sukumaran DK, Xiao R, Yee A, Lemak A, Bhattacharya A, Acton TA, Arrowsmith CH, Montelione GT, Szyperski T. Proc Natl Acad Sci U S A. 2005 Jul 26;102(30):10487-92.
General references[]
- Gordon S. Rule, T. Kevin Hitchens (2006). "Fundamentals of Protein NMR Spectroscopy". Springer. ISBN 1-4020-3499-7. http://www.springer.com/1-4020-3499-7
- Quincy Teng, (2005). "Structural Biology, Practical NMR Applications, Springer, ISBN 0-387-24367-4
- John Cavanagh, Wayne J. Fairbrother, Arthur G. Palmer III, Nicholas J. Skelton, (1995). Protein NMR Spectroscopy : Principles and Practice. Academic Press. ISBN 0-12-164490-1.
- Kurt Wuthrich (1986) NMR of Proteins and Nucleic Acids . Wiley-Interscience. ISBN 0-47-182893-9
Template:Protein structure determination
| This page uses Creative Commons Licensed content from Wikipedia (view authors). |