Assessment |
Biopsychology |
Comparative |
Cognitive |
Developmental |
Language |
Individual differences |
Personality |
Philosophy |
Social |
Methods |
Statistics |
Clinical |
Educational |
Industrial |
Professional items |
World psychology |
Other fields of psychology: AI · Computer · Consulting · Consumer · Engineering · Environmental · Forensic · Military · Sport · Transpersonal · Index
The perceptron is a type of artificial neural network invented in 1957 at the Cornell Aeronautical Laboratory by Frank Rosenblatt. It can be seen as the simplest kind of feedforward neural network: a linear classifier.
Definition[]
The perceptron is a kind of binary classifier that maps its input (a real-valued vector in the simplest case) to an output value calculated as



where is a vector of weights and denotes dot product. (We use the dot product as we are computing a weighted sum.) The sign of is used to classify as either a positive or a negative instance. Since the inputs are fed directly to the output via the weights, the perceptron can be considered the simplest kind of feedforward network.


Learning algorithm[]
In order to describe the training procedure, let denote a training set of examples where denotes the input and denotes the desired output for the input of the i-th example. We use to refer to the output of the network presented with training example . For convenience, we assume unipolar values for the neurons, i.e. for positive examples and for negative ones.







When the training set is linearly separable, there exists a weight vector such that for all , the perceptron can be trained by a simple online learning algorithm in which examples are presented iteratively and corrections to the weight vectors are made each time a mistake occurs (learning by examples). The correction to the weight vector when a mistake occurs is (with learning rate ). Novikoff (1962) proved that this algorithm converges after a finite number of iterations.





However, if the training set is not linearly separable, the above online algorithm will never converge.
Variants[]
The pocket algorithm with ratchet (Gallant, 1990) solves the stability problem of perceptron learning by keeping the best solution seen so far "in its pocket". The pocket algorithm then returns the solution in the pocket, rather than the last solution.
The -perceptron further utilised a preprocessing layer of fixed random weights, with thresholded output units. This enabled the perceptron to classify analogue patterns, by projecting them into a binary space. In fact, for a projection space of sufficiently high dimension, patterns can become linearly separable.

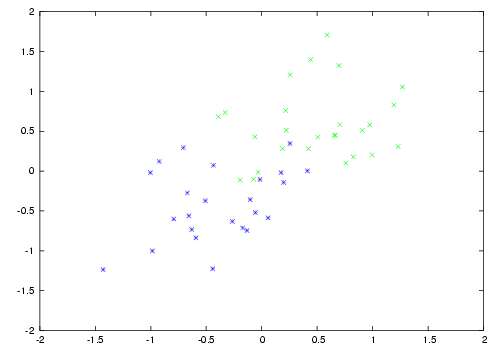
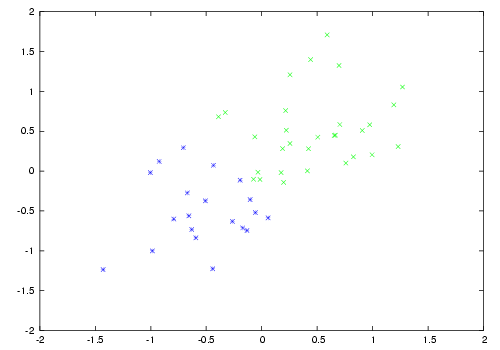
As an example, consider the case of having to classify data into two classes. Here is a small such dataset, consisting of two points coming from two Gaussian distributions.
{kind=link}
Two class gaussian data
{kind=link}
A linear classifier operating on the original space

{kind=link}
A linear classifier operating on a high-dimensional projection
A linear classifier can only separate things with a hyperplane, so it's not possible to perfectly classify all the examples. On the other hand, we may project the data into a large number of dimensions. In this case a random matrix was used to project the data linearly to a 1000-dimensional space; then each resulting data point was transformed through the hyperbolic tangent function. A linear classifier can then separate the data, as shown in the third figure. However the data may still not be completely separable in this space, in which the perceptron algorithm would not converge. In the example shown, stochastic steepest gradient descent was used to adapt the parameters.
It should be kept in mind, however, that the best classifier is not necessarily that which classifies all the training data perfectly. Indeed, if we had the prior constraint that the data come from equi-variant Gaussian distributions, the linear separation in the input space is optimal.
Other training algorithms for linear classifiers are possible: see, e.g., support vector machine and logistic regression.
History[]
Although the perceptron initially seemed promising, it was quickly proved that perceptrons could not be trained to recognise many classes of patterns. This led to the field of neural network research stagnating for many years, before it was recognised that a feedforward neural network with three or more layers (also called a multilayer perceptron) had far greater processing power than perceptrons with one layer (also called a single layer perceptron) or two. Single layer perceptrons are only capable of learning linearly separable patterns; in 1969 a famous monograph entitled Perceptrons by Marvin Minsky and Seymour Papert showed that it was impossible for these classes of network to learn an XOR function. They conjectured (incorrectly) that a similar result would hold for a perceptron with three or more layers. 3 Years later Stephen Grossberg published a series of papers introducing networks capable of modelling differential, contrast-enhancing and XOR functions. (the papers were published in 1972 and 1973, see e.g.: Grossberg, Contour enhancement, short-term memory, and constancies in reverberating neural networks. Studies in Applied Mathematics, 52 (1973), 213-257, online [1]). Nevertheless the often-cited Minsky/Papert text caused a significant decline in interest and funding of neural network research. It took ten more years for until the neural network research experienced a resurgence in the 1980s.
More recently, interest in the perceptron learning algorithm has increased again after Freund and Schapire (1998) presented a voted formulation of the original algorithm (attaining large margin) and suggested that one can apply the kernel trick to it. The kernel-perceptron not only can handle nonlinearly separable data but can also go beyond vectors and classify instances having a relational representation (e.g. trees, graphs or sequences).
See also[]
- Artificial intelligence
- Artificial neural network
- Data mining
- Linear classifier
- Linear discriminant analysis
- Logit and Logistic regression
- Machine learning
- Pattern recognition
- Support vector machines
References[]
- Freund, Y. and Schapire, R. E. 1998. Large margin classification using the perceptron algorithm. In Proceedings of the 11th Annual Conference on Computational Learning Theory (COLT' 98). ACM Press.
- Gallant, S. I. (1990). Perceptron-based learning algorithms. IEEE Transactions on Neural Networks, vol. 1, no. 2, pp. 179-191.
- Rosenblatt, Frank (1958), The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain, Cornell Aeronautical Laboratory, Psychological Review, v65, No. 6, pp. 386-408.
- Minsky M L and Papert S A 1969 Perceptrons (Cambridge, MA: MIT Press)
- Novikoff, A. B. (1962). On convergence proofs on perceptrons. Symposium on the Mathematical Theory of Automata, 12, 615-622. Polytechnic Institute of Brooklyn.
- Widrow, B., Lehr, M.A., "30 years of Adaptive Neural Networks: Peceptron, Madaline, and Backpropagation," Proc. IEEE, vol 78, no 9, pp. 1415-1442, (1990).
External links[]
- History of perceptrons
- Mathematics of perceptrons
- Perceptron demo applet
- Perceptron demo applet and an introduction by examples
"Perceptron" is also the name of a Michigan company that sells technology products to automakers.
de:Perzeptron es:Perceptrón fr:Perceptron nl:Perceptron sl:Perceptron sv:Perceptron th:เพอร์เซปตรอน
| This page uses Creative Commons Licensed content from Wikipedia (view authors). |