No edit summary |
No edit summary |
||
| Line 1: | Line 1: | ||
{{StatsPsy}} |
{{StatsPsy}} |
||
| + | [[Image:KurtosisChanges.png|thumb|200px|The far red light has no effect on the average speed of the gravitropic reaction in [[wheat]] [[coleoptile]]s, but it changes kurtosis from platykurtic to leptokurtic (-0.194 → 0.055)]] |
||
In [[probability theory]] and [[statistics]], '''kurtosis''' is a measure of the "peakedness" of the [[probability distribution]] of a [[real number|real]]-valued [[random variable]]. Higher kurtosis means more of the [[variance]] is due to infrequent extreme deviations, as opposed to frequent modestly-sized deviations. |
In [[probability theory]] and [[statistics]], '''kurtosis''' is a measure of the "peakedness" of the [[probability distribution]] of a [[real number|real]]-valued [[random variable]]. Higher kurtosis means more of the [[variance]] is due to infrequent extreme deviations, as opposed to frequent modestly-sized deviations. |
||
| Line 7: | Line 8: | ||
The fourth [[standardized moment]] is defined as μ<sub>4</sub> / σ<sup>4</sup>, where μ<sub>4</sub> is the fourth [[moment about the mean]] and σ is the [[standard deviation]]. This is sometimes used as the definition of kurtosis in older works, but is not the definition used here. |
The fourth [[standardized moment]] is defined as μ<sub>4</sub> / σ<sup>4</sup>, where μ<sub>4</sub> is the fourth [[moment about the mean]] and σ is the [[standard deviation]]. This is sometimes used as the definition of kurtosis in older works, but is not the definition used here. |
||
| − | Kurtosis is more commonly defined as the |
+ | Kurtosis is more commonly defined as the fourth [[cumulant]] divided by the square of the [[variance]] of the probability distribution, |
:<math>\gamma_2 = \frac{\kappa_4}{\kappa_2^2} = \frac{\mu_4}{\sigma^4} - 3, \!</math> |
:<math>\gamma_2 = \frac{\kappa_4}{\kappa_2^2} = \frac{\mu_4}{\sigma^4} - 3, \!</math> |
||
| − | which is |
+ | which is known as '''excess kurtosis'''. The "minus 3" at the end of this formula is often explained as a correction to make the kurtosis of the normal distribution equal to zero. Another reason can be seen by looking at the formula for the kurtosis of the sum of random variables. Because of the use of the cumulant, if ''Y'' is the sum of ''n'' [[statistical independence|independent]] random variables, all with the same distribution as ''X'', then Kurt[''Y''] = Kurt[''X''] / ''n'', while the formula would be more complicated if kurtosis were defined as μ<sub>4</sub> / σ<sup>4</sup>. |
| + | |||
| + | More generally, if ''X''<sub>1</sub>, ..., ''X''<sub>''n''</sub> are independent random variables all having the '''same variance''', then |
||
| + | |||
| + | :<math>\operatorname{Kurt}\left(\sum_{i=1}^n X_i \right) = {1 \over n^2} \sum_{i=1}^n \operatorname{Kurt}(X_i),</math> |
||
| + | |||
| + | whereas this identity would not hold if the definition did not include the subtraction of 3. |
||
| + | |||
| + | <!-- Kurtosis can range from −2 to +infinity. --> |
||
== Terminology and examples == |
== Terminology and examples == |
||
| Line 17: | Line 26: | ||
A high kurtosis distribution has a sharper "peak" and fatter "tails", while a low kurtosis distribution has a more rounded peak with wider "shoulders". |
A high kurtosis distribution has a sharper "peak" and fatter "tails", while a low kurtosis distribution has a more rounded peak with wider "shoulders". |
||
| − | Distributions with zero kurtosis are called '''mesokurtic'''. The most prominent example of a mesokurtic distribution is the [[normal distribution]] family, regardless of the values of its [[parameter]]s. A few other well-known distributions can be mesokurtic, depending on parameter values: for example the [[binomial distribution]] is mesokurtic for <math>p = 1/2 \pm \sqrt{1/12}</math>. |
+ | Distributions with zero kurtosis are called '''mesokurtic''', or mesokurtotic. The most prominent example of a mesokurtic distribution is the [[normal distribution]] family, regardless of the values of its [[parameter]]s. A few other well-known distributions can be mesokurtic, depending on parameter values: for example the [[binomial distribution]] is mesokurtic for <math>p = 1/2 \pm \sqrt{1/12}</math>. |
| − | A distribution with [[negative and non-negative numbers|positive]] kurtosis is called '''leptokurtic'''. In terms of shape, a leptokurtic distribution has a more acute "peak" around the [[mean]] (that is, a higher probability than a normally distributed variable of values near the mean) and "fat |
+ | A distribution with [[negative and non-negative numbers|positive]] kurtosis is called '''leptokurtic''', or leptokurtotic. In terms of shape, a leptokurtic distribution has a more acute "peak" around the [[mean]] (that is, a higher probability than a normally distributed variable of values near the mean) and "[[fat tail]]s" (that is, a higher probability than a normally distributed variable of [[extreme value]]s). Examples of leptokurtic distributions include the [[Laplace distribution]] and the [[logistic distribution]]. |
| − | A distribution with negative kurtosis is called '''platykurtic'''. In terms of shape, a platykurtic distribution has a smaller "peak" around the mean (that is, a lower probability than a normally distributed variable of values near the mean) and "thin tails" (that is, a lower probability than a normally distributed variable of [[extreme value]]s). Examples of platykurtic distributions include the |
+ | A distribution with negative kurtosis is called '''platykurtic''', or platykurtotic. In terms of shape, a platykurtic distribution has a smaller "peak" around the mean (that is, a lower probability than a normally distributed variable of values near the mean) and "thin tails" (that is, a lower probability than a normally distributed variable of [[extreme value]]s). Examples of platykurtic distributions include the continuous or discrete [[uniform distribution]]s, and the [[raised cosine distribution]]. The most platykurtic distribution of all is the [[Bernoulli distribution]] with ''p'' = ½ (for example the number of times one obtains "heads" when flipping a coin once), for which the kurtosis is -2. |
| + | |||
| + | == Graphical examples == |
||
| + | === The Pearson type VII family === |
||
| + | |||
| + | [[Image:Pearson type VII distribution PDF.png|300px|thumb|pdf for the Pearson type VII distribution with kurtosis of infinity (red); 2 (blue); and 0 (black)]] |
||
| + | [[Image:Pearson type VII distribution log-PDF.png|300px|thumb|log-pdf for the Pearson type VII distribution with kurtosis of infinity (red); 2 (blue); 1, 1/2, 1/4, 1/8, and 1/16 (gray); and 0 (black)]] |
||
| + | |||
| + | We illustrate the effects of kurtosis using a parametric family of distributions whose kurtosis can be adjusted while their lower-order moments and cumulants remain constant. Consider the [[Pearson distribution|Pearson type VII family]], which is a special case of the [[Pearson distribution|Pearson type IV family]] restricted to symmetric densities. The probability density function is given by |
||
| + | |||
| + | :<math>f(x; a, m) = \frac{\Gamma(m)}{a\,\sqrt{\pi}\,\Gamma(m-1/2)} \left[1+\left(\frac{x}{a}\right)^2 \right]^{-m}, \!</math> |
||
| + | |||
| + | where ''a'' is a [[scale parameter]] and ''m'' is a [[shape parameter]]. |
||
| + | |||
| + | All densities in this family are symmetric. The ''k''th moment exists provided <math>m>(k+1)/2</math>. For the kurtosis to exist, we require <math>m>5/2</math>. Then the mean and skewness exist and are both identically zero. Setting <math>a^2 = 2m-3</math> makes the variance equal to unity. Then the only free parameter is ''m'', which controls the fourth moment (and cumulant) and hence the kurtosis. One can reparameterize with <math>m = 5/2 + 3/\gamma_2</math>, where <math>\gamma_2</math> is the kurtosis as defined above. This yields a one-parameter leptokurtic family with zero mean, unit variance, zero skewness, and arbitrary positive kurtosis. The reparameterized density is |
||
| + | |||
| + | :<math>g(x; \gamma_2) = f(x;\; a=\sqrt{2+6/\gamma_2},\; m=5/2+3/\gamma_2). \!</math> |
||
| + | |||
| + | In the limit as <math>\gamma_2 \to \infty</math> one obtains the density |
||
| + | |||
| + | :<math>g(x) = 3 \left(2 + x^2\right)^{-5/2}, \!</math> |
||
| + | |||
| + | which is shown as the red curve in the images on the right. |
||
| + | |||
| + | In the other direction as <math>\gamma_2 \to 0</math> one obtains the [[normal distribution|standard normal]] density as the limiting distribution, shown as the black curve. |
||
| + | |||
| + | In the images on the right, the blue curve represents the density <math>x \mapsto g(x; 2)</math> with kurtosis of 2. The top image shows that leptokurtic densities in this family have a higher peak than the mesokurtic normal density. The comparatively fatter tails of the leptokurtic densities are illustrated in the second image, which plots the natural logarithm of the Pearson type VII densities: the black curve is the logarithm of the standard normal density, which is an inverted [[parabola]]. One can see that the normal density allocates little probability mass to the regions far from the mean ("has thin tails"), compared with the blue curve of the leptokurtic Pearson type VII density with kurtosis of 2. Between the blue curve and the black are other Pearson type VII densities with γ<sub>2</sub> = 1, 1/2, 1/4, 1/8, and 1/16. The red curve again shows the upper limit of the Pearson type VII family, with <math>\gamma_2 = \infty</math> (which, strictly speaking, means that the fourth moment does not exist). The red curve decreases the slowest as one moves outward from the origin ("has fat tails"). |
||
| + | |||
| + | === Kurtosis of well-known distributions === |
||
| + | |||
| + | [[Image:Standard symmetric pdfs.png|300px|thumb]] |
||
| + | [[Image:Standard symmetric pdfs logscale.png|300px|thumb]] |
||
| + | |||
| + | In this example we compare several well-known distributions from different parametric families. All densities considered here are unimodal and symmetric. Each has a mean and skewness of zero. Parameters were chosen to result in a variance of unity in each case. The images on the right show curves for the following seven densities, on a linear scale and logarithmic scale: |
||
| + | |||
| + | * D: [[Laplace distribution]], a/k/a double exponential distribution, red curve (two straight lines in the log-scale plot), kurtosis 3 (leptokurtic) |
||
| + | * S: [[hyperbolic secant distribution]], orange curve, kurtosis 2 (leptokurtic) |
||
| + | * L: [[logistic distribution]], green curve, kurtosis 1.2 (leptokurtic) |
||
| + | * N: [[normal distribution]], black curve (inverted parabola in the log-scale plot), kurtosis 0 (mesokurtic) |
||
| + | * C: [[raised cosine distribution]], cyan curve, kurtosis −0.593762… (platykurtic) |
||
| + | * W: [[Wigner semicircle distribution]], blue curve, kurtosis −1 (platykurtic) |
||
| + | * U: [[uniform distribution (continuous)|uniform distribution]], magenta curve (shown for clarity as a rectangle in both images), kurtosis −1.2 (platykurtic) |
||
| + | |||
| + | Note that in this case the platykurtic densities have bounded support, whereas the densities with nonnegative kurtosis are supported on the whole [[real line]]. In general there exist platykurtic densities with infinite support, for example [[exponential power distribution]]s with sufficiently large shape parameter ''b''. |
||
== Sample kurtosis == |
== Sample kurtosis == |
||
| Line 30: | Line 82: | ||
where ''m''<sub>4</sub> is the fourth sample [[moment about the mean]], ''m''<sub>2</sub> is the second sample moment about the mean (that is, the [[sample variance]]), ''x''<sub>''i''</sub> is the ''i''<sup>th</sup> value, and <math>\overline{x}</math> is the [[sample mean]]. |
where ''m''<sub>4</sub> is the fourth sample [[moment about the mean]], ''m''<sub>2</sub> is the second sample moment about the mean (that is, the [[sample variance]]), ''x''<sub>''i''</sub> is the ''i''<sup>th</sup> value, and <math>\overline{x}</math> is the [[sample mean]]. |
||
| + | |||
| + | The formula |
||
| + | :<math> D = {1 \over n} \sum_{i=1}^n{ (x_i - \bar{x})^2} </math>, |
||
| + | :<math> E = {1 \over n D^2} \sum_{i=1}^n{ (x_i - \bar{x})^4} - 3 </math> |
||
| + | is also used, where n - the sample size, ''D'' - the pre-computed variance, x<sub>i</sub> - the value of the x'th measurement and <math>\bar{x}</math> - the pre-computed arithmetic mean. |
||
== Estimators of population kurtosis == |
== Estimators of population kurtosis == |
||
| − | Given a sub-set of samples from a population, the sample kurtosis above is a [[biased estimator]] of the population kurtosis. The usual estimator of the population kurtosis (used in [[SAS System|SAS]], [[SPSS]], and [[Excel]] but not by [[MINITAB]] or [[BMDP]]) is ''G''<sub>2</sub>, defined as follows: |
+ | Given a sub-set of samples from a population, the sample kurtosis above is a [[biased estimator]] of the population kurtosis. The usual estimator of the population kurtosis (used in [[SAS System|SAS]], [[SPSS]], and [[Microsoft Excel|Excel]] but not by [[MINITAB]] or [[BMDP]]) is ''G''<sub>2</sub>, defined as follows: |
{|- |
{|- |
||
|<math>G_2 \!\!\!\!</math> |
|<math>G_2 \!\!\!\!</math> |
||
| Line 58: | Line 115: | ||
* [[skewness]] |
* [[skewness]] |
||
| + | * [[Skewness risk]] |
||
| + | * [[kurtosis risk]] |
||
==References== |
==References== |
||
| − | * Joanes,<!--sic--> D. N. & Gill, C. A. (1998) Comparing measures of sample skewness and kurtosis. ''Journal of the |
+ | * Joanes,<!--sic--> D. N. & Gill, C. A. (1998) Comparing measures of sample skewness and kurtosis. ''Journal of the Royal Statistical Society (Series D): The Statistician'' '''47''' (1), 183–189. [http://dx.doi.org/10.1111/1467-9884.00122 doi:10.1111/1467-9884.00122] |
== External links == |
== External links == |
||
| + | * [http://www.patternrecognition.co.za Matlab implementation of kurtosis and other statistical measures] |
||
| − | * [http://www.wessa.net/skewkurt.wasp Free Online Software (Calculator)] computes various types of skewness and kurtosis statistics for any dataset (includes small and large sample tests). |
+ | * [http://www.wessa.net/skewkurt.wasp Free Online Software (Calculator)] computes various types of skewness and kurtosis statistics for any dataset (includes small and large sample tests).. |
| + | *[http://members.aol.com/jeff570/k.html Kurtosis] on the [http://members.aol.com/jeff570/mathword.html Earliest known uses of some of the words of mathematics] |
||
| + | *[http://www.etsu.edu/math/seier/Kurto100years.doc Celebrating 100 years of Kurtosis] a history of the topic, with different measures of kurtosis. |
||
| + | |||
[[Category:Probability theory]] |
[[Category:Probability theory]] |
||
| − | [[Category: |
+ | [[Category:Statistical deviation and dispersion]] |
| + | <!-- |
||
[[de:Wölbung (Statistik)]] |
[[de:Wölbung (Statistik)]] |
||
| + | [[es:Curtosis]] |
||
[[fr:Kurtosis]] |
[[fr:Kurtosis]] |
||
[[it:Curtosi]] |
[[it:Curtosi]] |
||
| + | [[he:גבנוניות (סטטיסטיקה)]] |
||
| + | [[lv:Ekscesa koeficients]] |
||
| + | [[lt:Ekscesas]] |
||
| + | [[hu:Lapultság]] |
||
| + | [[nl:Kurtosis]] |
||
| + | [[ja:尖度]] |
||
[[pl:Kurtoza]] |
[[pl:Kurtoza]] |
||
[[pt:Curtose]] |
[[pt:Curtose]] |
||
| + | [[ru:Коэффициент эксцесса]] |
||
[[su:Kurtosis]] |
[[su:Kurtosis]] |
||
| + | [[sv:Kurtosis]] |
||
| + | ---> |
||
{{enWP|Kurtosis}} |
{{enWP|Kurtosis}} |
||
Revision as of 06:52, 2 April 2007
Assessment |
Biopsychology |
Comparative |
Cognitive |
Developmental |
Language |
Individual differences |
Personality |
Philosophy |
Social |
Methods |
Statistics |
Clinical |
Educational |
Industrial |
Professional items |
World psychology |
Statistics: Scientific method · Research methods · Experimental design · Undergraduate statistics courses · Statistical tests · Game theory · Decision theory
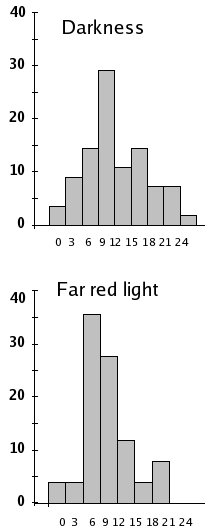
The far red light has no effect on the average speed of the gravitropic reaction in wheat coleoptiles, but it changes kurtosis from platykurtic to leptokurtic (-0.194 → 0.055)
In probability theory and statistics, kurtosis is a measure of the "peakedness" of the probability distribution of a real-valued random variable. Higher kurtosis means more of the variance is due to infrequent extreme deviations, as opposed to frequent modestly-sized deviations.
Definition of kurtosis
The fourth standardized moment is defined as μ4 / σ4, where μ4 is the fourth moment about the mean and σ is the standard deviation. This is sometimes used as the definition of kurtosis in older works, but is not the definition used here.
Kurtosis is more commonly defined as the fourth cumulant divided by the square of the variance of the probability distribution,

which is known as excess kurtosis. The "minus 3" at the end of this formula is often explained as a correction to make the kurtosis of the normal distribution equal to zero. Another reason can be seen by looking at the formula for the kurtosis of the sum of random variables. Because of the use of the cumulant, if Y is the sum of n independent random variables, all with the same distribution as X, then Kurt[Y] = Kurt[X] / n, while the formula would be more complicated if kurtosis were defined as μ4 / σ4.
More generally, if X1, ..., Xn are independent random variables all having the same variance, then

whereas this identity would not hold if the definition did not include the subtraction of 3.
Terminology and examples
A high kurtosis distribution has a sharper "peak" and fatter "tails", while a low kurtosis distribution has a more rounded peak with wider "shoulders".
Distributions with zero kurtosis are called mesokurtic, or mesokurtotic. The most prominent example of a mesokurtic distribution is the normal distribution family, regardless of the values of its parameters. A few other well-known distributions can be mesokurtic, depending on parameter values: for example the binomial distribution is mesokurtic for .

A distribution with positive kurtosis is called leptokurtic, or leptokurtotic. In terms of shape, a leptokurtic distribution has a more acute "peak" around the mean (that is, a higher probability than a normally distributed variable of values near the mean) and "fat tails" (that is, a higher probability than a normally distributed variable of extreme values). Examples of leptokurtic distributions include the Laplace distribution and the logistic distribution.
A distribution with negative kurtosis is called platykurtic, or platykurtotic. In terms of shape, a platykurtic distribution has a smaller "peak" around the mean (that is, a lower probability than a normally distributed variable of values near the mean) and "thin tails" (that is, a lower probability than a normally distributed variable of extreme values). Examples of platykurtic distributions include the continuous or discrete uniform distributions, and the raised cosine distribution. The most platykurtic distribution of all is the Bernoulli distribution with p = ½ (for example the number of times one obtains "heads" when flipping a coin once), for which the kurtosis is -2.
Graphical examples
The Pearson type VII family
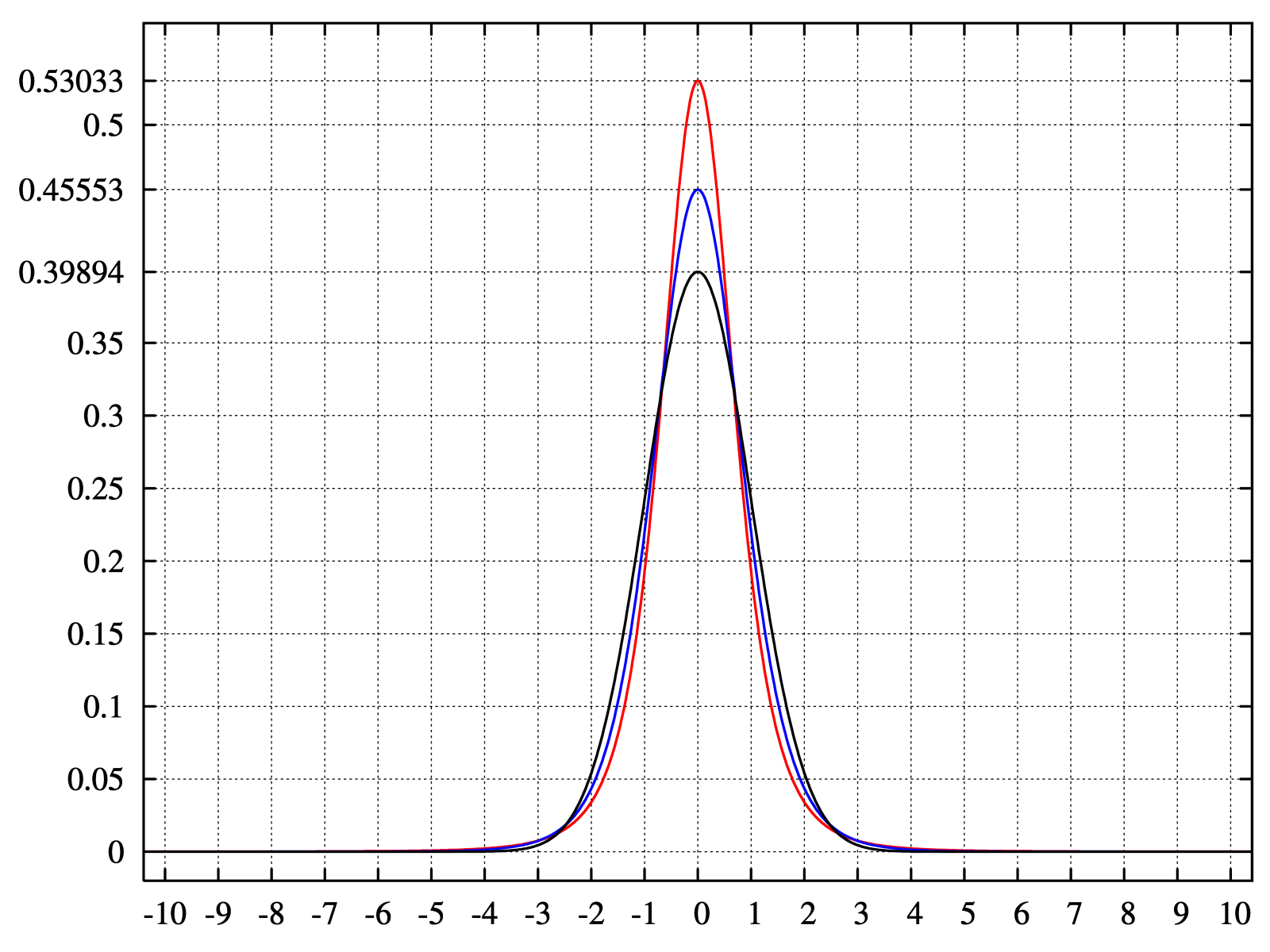
pdf for the Pearson type VII distribution with kurtosis of infinity (red); 2 (blue); and 0 (black)

log-pdf for the Pearson type VII distribution with kurtosis of infinity (red); 2 (blue); 1, 1/2, 1/4, 1/8, and 1/16 (gray); and 0 (black)
We illustrate the effects of kurtosis using a parametric family of distributions whose kurtosis can be adjusted while their lower-order moments and cumulants remain constant. Consider the Pearson type VII family, which is a special case of the Pearson type IV family restricted to symmetric densities. The probability density function is given by
![{\displaystyle f(x;a,m)={\frac {\Gamma (m)}{a\,{\sqrt {\pi }}\,\Gamma (m-1/2)}}\left[1+\left({\frac {x}{a}}\right)^{2}\right]^{-m},\!}](https://services.fandom.com/mathoid-facade/v1/media/math/render/svg/4684045ee3b165e4a0bb7f62314ce3fb6b265dc7)
where a is a scale parameter and m is a shape parameter.
All densities in this family are symmetric. The kth moment exists provided . For the kurtosis to exist, we require . Then the mean and skewness exist and are both identically zero. Setting makes the variance equal to unity. Then the only free parameter is m, which controls the fourth moment (and cumulant) and hence the kurtosis. One can reparameterize with , where is the kurtosis as defined above. This yields a one-parameter leptokurtic family with zero mean, unit variance, zero skewness, and arbitrary positive kurtosis. The reparameterized density is






In the limit as one obtains the density


which is shown as the red curve in the images on the right.
In the other direction as one obtains the standard normal density as the limiting distribution, shown as the black curve.

In the images on the right, the blue curve represents the density with kurtosis of 2. The top image shows that leptokurtic densities in this family have a higher peak than the mesokurtic normal density. The comparatively fatter tails of the leptokurtic densities are illustrated in the second image, which plots the natural logarithm of the Pearson type VII densities: the black curve is the logarithm of the standard normal density, which is an inverted parabola. One can see that the normal density allocates little probability mass to the regions far from the mean ("has thin tails"), compared with the blue curve of the leptokurtic Pearson type VII density with kurtosis of 2. Between the blue curve and the black are other Pearson type VII densities with γ2 = 1, 1/2, 1/4, 1/8, and 1/16. The red curve again shows the upper limit of the Pearson type VII family, with (which, strictly speaking, means that the fourth moment does not exist). The red curve decreases the slowest as one moves outward from the origin ("has fat tails").


Kurtosis of well-known distributions
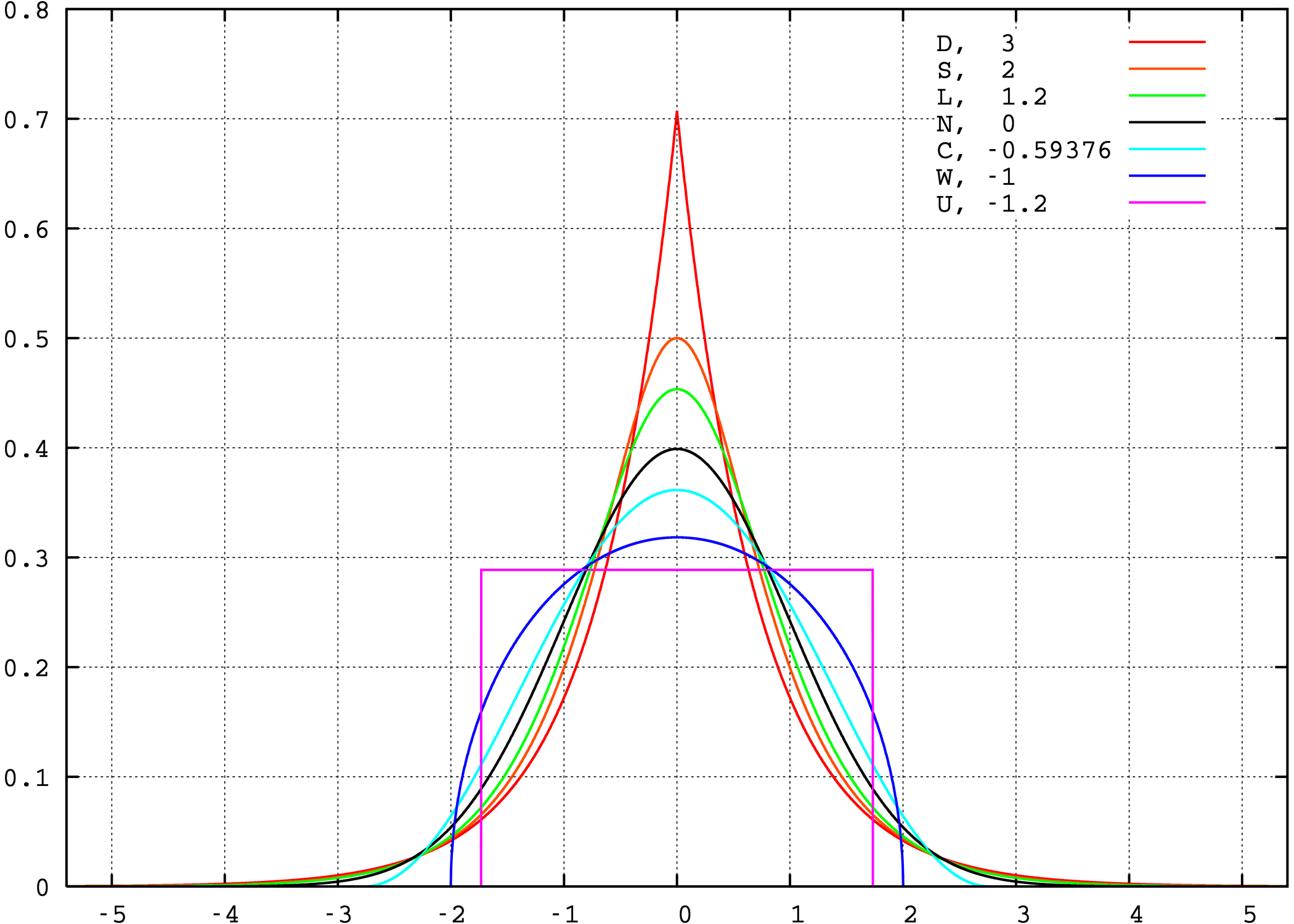
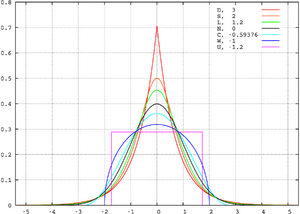

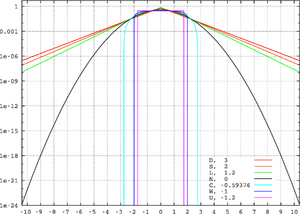
In this example we compare several well-known distributions from different parametric families. All densities considered here are unimodal and symmetric. Each has a mean and skewness of zero. Parameters were chosen to result in a variance of unity in each case. The images on the right show curves for the following seven densities, on a linear scale and logarithmic scale:
- D: Laplace distribution, a/k/a double exponential distribution, red curve (two straight lines in the log-scale plot), kurtosis 3 (leptokurtic)
- S: hyperbolic secant distribution, orange curve, kurtosis 2 (leptokurtic)
- L: logistic distribution, green curve, kurtosis 1.2 (leptokurtic)
- N: normal distribution, black curve (inverted parabola in the log-scale plot), kurtosis 0 (mesokurtic)
- C: raised cosine distribution, cyan curve, kurtosis −0.593762… (platykurtic)
- W: Wigner semicircle distribution, blue curve, kurtosis −1 (platykurtic)
- U: uniform distribution, magenta curve (shown for clarity as a rectangle in both images), kurtosis −1.2 (platykurtic)
Note that in this case the platykurtic densities have bounded support, whereas the densities with nonnegative kurtosis are supported on the whole real line. In general there exist platykurtic densities with infinite support, for example exponential power distributions with sufficiently large shape parameter b.
Sample kurtosis
For a sample of n values the sample kurtosis is

where m4 is the fourth sample moment about the mean, m2 is the second sample moment about the mean (that is, the sample variance), xi is the ith value, and is the sample mean.

The formula
- ,


is also used, where n - the sample size, D - the pre-computed variance, xi - the value of the x'th measurement and - the pre-computed arithmetic mean.

Estimators of population kurtosis
Given a sub-set of samples from a population, the sample kurtosis above is a biased estimator of the population kurtosis. The usual estimator of the population kurtosis (used in SAS, SPSS, and Excel but not by MINITAB or BMDP) is G2, defined as follows:







where k4 is the unique symmetric unbiased estimator of the fourth cumulant, k2 is the unbiased estimator of the population variance, m4 is the fourth sample moment about the mean, m2 is the sample variance, xi is the ith value, and is the sample mean. Unfortunately, is itself generally biased. For the normal distribution it is unbiased because its expected value is then zero.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
See also
- skewness
- Skewness risk
- kurtosis risk
References
- Joanes, D. N. & Gill, C. A. (1998) Comparing measures of sample skewness and kurtosis. Journal of the Royal Statistical Society (Series D): The Statistician 47 (1), 183–189. doi:10.1111/1467-9884.00122
External links
- Matlab implementation of kurtosis and other statistical measures
- Free Online Software (Calculator) computes various types of skewness and kurtosis statistics for any dataset (includes small and large sample tests)..
- Kurtosis on the Earliest known uses of some of the words of mathematics
- Celebrating 100 years of Kurtosis a history of the topic, with different measures of kurtosis.
| This page uses Creative Commons Licensed content from Wikipedia (view authors). |