(→Science of state: started tidy) |
m (Reverted edits by 112.206.146.104 (talk | block) to last version by Dr Joe Kiff) |
||
| (7 intermediate revisions by 4 users not shown) | |||
| Line 19: | Line 19: | ||
===Origins in probability=== |
===Origins in probability=== |
||
| − | The mathematical methods of statistics emerged from [[probability theory]], which can be dated to the correspondence of |
+ | The mathematical methods of statistics emerged from [[probability theory]], which can be dated to the correspondence of Pierre de Fermat and Blaise Pascal (1654). Christiaan Huygens (1657) gave the earliest known scientific treatment of the subject. Jakob Bernoulli's ''Ars Conjectandi'' (posthumous, 1713) and Abraham de Moivre's ''[[Doctrine of Chances]]'' (1718) treated the subject as a branch of mathematics. <ref> See [[Ian Hacking]]'s ''The Emergence of Probability'' for a history of the early development of the very concept of mathematical probability. </ref> |
| − | The [[theory of errors]] may be traced back to |
+ | The [[theory of errors]] may be traced back to Roger Cotes's ''Opera Miscellanea'' (posthumous, 1722), but a memoir prepared by Thomas Simpson in 1755 (printed 1756) first applied the theory to the discussion of errors of observation. The reprint (1757) of this memoir lays down the [[axiom]]s that positive and negative errors are equally probable, and that there are certain assignable limits within which all errors may be supposed to fall; continuous errors are discussed and a probability curve is given. |
| − | + | Pierre-Simon Laplace (1774) made the first attempt to deduce a rule for the combination of observations from the principles of the theory of probabilities. He represented the law of probability of errors by a curve. He deduced a formula for the mean of three observations. He also gave (1781) a formula for the law of facility of error (a term due to Lagrange, 1774), but one which led to unmanageable equations. Daniel Bernoulli (1778) introduced the principle of the maximum product of the probabilities of a system of concurrent errors. |
|
| − | The [[method of least squares]], which was used to minimize errors in data [[measurement]], is due to |
+ | The [[method of least squares]], which was used to minimize errors in data [[measurement]], is due to Adrien-Marie Legendre (1805), who introduced it in his ''Nouvelles méthodes pour la détermination des orbites des comètes'' (''New Methods for Determining the Orbits of Comets''). In ignorance of Legendre's contribution, an Irish-American writer, Robert Adrain, editor of "The Analyst" (1808), first deduced the law of facility of error. He gave two proofs, the second being essentially the same as John Herschel's (1850). Carl Friedrich Gauss gave the first proof which seems to have been known in Europe (the third after Adrain's) in 1809. Further proofs were given by Laplace (1810, 1812), Gauss (1823), James Ivory (1825, 1826), Hagen (1837), Friedrich Bessel(1838), W. F. Donkin (1844, 1856), and Morgan Crofton (1870). |
| − | Other contributors were Ellis (1844), |
+ | Other contributors were Ellis (1844), Augustus De Morgan (1864), Glaisher (1872), and Giovanni Schiaparelli (1875). Peters's (1856) formula for <math>r</math>, the probable error of a single observation, is well known. |
| − | In the |
+ | In the nineteenth century authors on the general theory included Laplace, Sylvestre Lacroix(1816), Littrow (1833), Richard Dedekind (1860), Helmert (1872), Hermann Laurent(1873), Liagre, Didion, and [[Karl Pearson]]. Augustus De Morgan and George Boole improved the exposition of the theory. |
[[Adolphe Quetelet]] (1796-1874), another important founder of statistics, introduced the notion of the "average man" (''l'homme moyen'') as a means of understanding complex social phenomena such as [[crime rates]], [[marriage rates]] or [[suicide rates]]. |
[[Adolphe Quetelet]] (1796-1874), another important founder of statistics, introduced the notion of the "average man" (''l'homme moyen'') as a means of understanding complex social phenomena such as [[crime rates]], [[marriage rates]] or [[suicide rates]]. |
||
| Line 36: | Line 36: | ||
Today the use of statistics has broadened far beyond its origins as a service to a state or government. Individuals and organizations use statistics to understand data and make informed decisions throughout the natural and social sciences, medicine, business, and other areas. |
Today the use of statistics has broadened far beyond its origins as a service to a state or government. Individuals and organizations use statistics to understand data and make informed decisions throughout the natural and social sciences, medicine, business, and other areas. |
||
| − | Statistics is generally regarded not as a subfield of mathematics but as a distinct, albeit allied, field. Many [[university|universities]] maintain separate mathematics and statistics |
+ | Statistics is generally regarded not as a subfield of mathematics but as a distinct, albeit allied, field. Many [[university|universities]] maintain separate mathematics and statistics departments. Statistics is also taught in departments as diverse as [[psychology]], [[education]], and [[public health]]. |
===Important contributors to statistics=== |
===Important contributors to statistics=== |
||
| Line 51: | Line 51: | ||
* [[Aleksandr Lyapunov]] |
* [[Aleksandr Lyapunov]] |
||
* [[Abraham De Moivre]] |
* [[Abraham De Moivre]] |
||
| − | * [[Isaac Newton]] |
||
* [[Florence Nightingale]] |
* [[Florence Nightingale]] |
||
* [[Blaise Pascal]] |
* [[Blaise Pascal]] |
||
| Line 114: | Line 113: | ||
==Specialized disciplines== |
==Specialized disciplines== |
||
Some sciences use [[applied statistics]] so extensively that they have [[specialized terminology]]. These disciplines include: |
Some sciences use [[applied statistics]] so extensively that they have [[specialized terminology]]. These disciplines include: |
||
| − | * [[Actuarial science]] |
||
* [[Biostatistics]] |
* [[Biostatistics]] |
||
| − | * [[Business statistics]] |
||
* [[Data mining]] (applying statistics and [[pattern recognition]] to discover knowledge from data) |
* [[Data mining]] (applying statistics and [[pattern recognition]] to discover knowledge from data) |
||
| − | * [[Economic statistics]] (Econometrics) |
||
| − | * [[Engineering statistics]] |
||
* [[Statistical physics]] |
* [[Statistical physics]] |
||
* [[Demography]] |
* [[Demography]] |
||
| Line 126: | Line 121: | ||
* [[Statistical literacy]] |
* [[Statistical literacy]] |
||
* [[Statistical survey]]s |
* [[Statistical survey]]s |
||
| − | * [[Process analysis]] and [[chemometrics]] (for analysis of data from [[analytical chemistry]] and [[chemical engineering]]) |
||
| − | * Reliability engineering |
||
| − | * Image processing |
||
| − | * Statistics in various sports, particularly [[Baseball statistics|baseball]] and [[Cricket statistics|cricket]] |
||
| + | |||
| − | Statistics form a key basis tool in business and manufacturing as well. It is used to understand measurement systems variability, control processes (as in [[statistical process control]] or SPC), for summarizing data, and to make data-driven decisions. In these roles it is a key tool, and perhaps the only reliable tool. |
||
==Software== |
==Software== |
||
| Line 139: | Line 130: | ||
== Criticism == |
== Criticism == |
||
| − | There is a general perception that statistical knowledge is all-too-frequently intentionally [[Misuse of statistics|misused]], by finding ways to interpret the data that are favorable to the presenter. (A famous quote, variously attributed, but thought to be from |
+ | There is a general perception that statistical knowledge is all-too-frequently intentionally [[Misuse of statistics|misused]], by finding ways to interpret the data that are favorable to the presenter. (A famous quote, variously attributed, but thought to be from Benjamin Disraeli <ref>cf. "Damned Lies and Statistics: Untangling Numbers from the Media, Politicians, and Activists" by Joel Best. Professor Best attributes it to Disraeli, rather than Mark Twain or others. </ref> is: "There are three types of lies - lies, damn lies, and statistics.") Indeed, the well-known book ''How to Lie with Statistics'' by Darrell Huff discusses many cases of deceptive uses of statistics, focusing on misleading graphs. By choosing (or rejecting, or modifying) a certain sample, results can be manipulated; throwing out [[outliers]] is one means of doing so. This may be the result of outright fraud or of subtle and unintentional bias on the part of the researcher. |
As further studies contradict previously announced results, people may become wary of trusting such studies. One might read a study that says (for example) "do X to reduce high blood pressure", followed by a study that says "doing X does not affect high blood pressure", followed by a study that says "doing X actually worsens high blood pressure". Often the studies were conducted on different groups with different protocols, or a small-sample study that promised intriguing results has not held up to further scrutiny in a large-sample study. However, many readers may not have noticed these distinctions, or the media may have oversimplified this vital contextual information, and the public's distrust of statistics is thereby increased. |
As further studies contradict previously announced results, people may become wary of trusting such studies. One might read a study that says (for example) "do X to reduce high blood pressure", followed by a study that says "doing X does not affect high blood pressure", followed by a study that says "doing X actually worsens high blood pressure". Often the studies were conducted on different groups with different protocols, or a small-sample study that promised intriguing results has not held up to further scrutiny in a large-sample study. However, many readers may not have noticed these distinctions, or the media may have oversimplified this vital contextual information, and the public's distrust of statistics is thereby increased. |
||
| Line 166: | Line 157: | ||
*[[Instrumental variables estimation]] |
*[[Instrumental variables estimation]] |
||
*[[List of academic statistical associations]] |
*[[List of academic statistical associations]] |
||
| − | *[[List of national and international statistical services]] |
||
*[[List of publications in statistics]] |
*[[List of publications in statistics]] |
||
*[[List of statistical topics]] |
*[[List of statistical topics]] |
||
| Line 177: | Line 167: | ||
*[[Resampling (statistics)]] |
*[[Resampling (statistics)]] |
||
*[[Statistical phenomena]] |
*[[Statistical phenomena]] |
||
| − | *[[Statistical thermodynamics]] |
||
*[[Statistician]] |
*[[Statistician]] |
||
*[[Structural equation modeling]] |
*[[Structural equation modeling]] |
||
| Line 183: | Line 172: | ||
*[[Scientific visualization]] |
*[[Scientific visualization]] |
||
| + | |||
| ⚫ | |||
| + | ==References & Bibliography== |
||
| ⚫ | |||
<references/> |
<references/> |
||
| − | ==Bibliography== |
+ | ===Bibliography=== |
*{{cite book |
*{{cite book |
||
| last = Desrosières |
| last = Desrosières |
||
| Line 243: | Line 234: | ||
| id = ISBN 0-520-21978-3 |
| id = ISBN 0-520-21978-3 |
||
}} |
}} |
||
| + | |||
| + | |||
| + | *Foster,J. Barkus,E. and Yavorsky,C. (2005).Understanding and Using Advanced Statistics: A Practical Guide for Students. London, Sage. ISBN 141290014X |
||
| + | |||
| + | *Parker,Ian (2005). Qualitative Psychology: Introducing Radical Research. Buckingham: Open University Press.ISBN: 0-335-21349-9 |
||
==External links== |
==External links== |
||
| Line 284: | Line 280: | ||
[[Category:Statistics|*]] |
[[Category:Statistics|*]] |
||
| − | [[af:Statistiek]] |
||
| − | [[ar:إحصاء]] |
||
| − | [[bg:Статистика]] |
||
| − | [[bn:পরিসংখ্যান]] |
||
| − | [[br:Stadegouriezh]] |
||
| − | [[ca:Estadística]] |
||
| − | [[cs:Statistika]] |
||
| − | [[cy:Ystadegaeth]] |
||
| − | [[da:Statistik]] |
||
| − | [[de:Statistik]] |
||
| − | [[dv:ތަފާސް ހިސާބު]] |
||
| − | [[el:Στατιστική]] |
||
| − | [[eo:Statistiko]] |
||
| − | [[es:Estadística]] |
||
| − | [[et:Statistika]] |
||
| − | [[fa:آمار]] |
||
| − | [[fi:Tilastotiede]] |
||
| − | [[fiu-vro:Statistiga]] |
||
| − | [[fr:Statistiques]] |
||
| − | [[fur:Statistiche]] |
||
| − | [[fy:Statistyk]] |
||
| − | [[ga:Staidreamh]] |
||
| − | [[gl:Estatística]] |
||
| − | [[gv:Steat-choontey]] |
||
| − | [[he:סטטיסטיקה]] |
||
| − | [[ia:Statistica]] |
||
| − | [[id:Statistika]] |
||
| − | [[io:Statistiko]] |
||
| − | [[is:Tölfræði]] |
||
| − | [[it:Statistica]] |
||
| − | [[iu:ᑭᓯᑦᓯᓯᖕᖑᕐᓗᒋᑦ ᐹᓯᔅᓱᑎᔅᓴᑦ]] |
||
| − | [[ja:統計学]] |
||
| − | [[jv:Statistika]] |
||
| − | [[ko:통계학]] |
||
| − | [[lb:Statistik]] |
||
| − | [[li:Sjtatistiek]] |
||
| − | [[lo:ສະຖິຕິສາດ]] |
||
| − | [[lt:Statistika]] |
||
| − | [[lv:Sjtatistiek]] |
||
| − | [[ms:Statistik]] |
||
| − | [[nl:Statistiek]] |
||
| − | [[nn:Statistikk]] |
||
| − | [[no:Statistikk]] |
||
| − | [[pl:Statystyka (nauka)]] |
||
| − | [[pt:Estatística]] |
||
| − | [[ro:Statistică]] |
||
| − | [[ru:Статистика]] |
||
| − | [[scn:Statìstica]] |
||
| − | [[simple:Statistics]] |
||
| − | [[sk:Štatistika]] |
||
| − | [[sl:Statistika]] |
||
| − | [[sr:Статистика]] |
||
| − | [[su:Statistik]] |
||
| − | [[sv:Statistik]] |
||
| − | [[th:สถิติศาสตร์]] |
||
| − | [[tl:Estadistika]] |
||
| − | [[vi:Thống kê]] |
||
| − | [[zh:统计学]] |
||
| − | [[zh-min-nan:Thóng-kè-ha̍k]] |
||
{{enWP|Statistics}} |
{{enWP|Statistics}} |
||
Latest revision as of 11:57, 24 August 2011
Assessment |
Biopsychology |
Comparative |
Cognitive |
Developmental |
Language |
Individual differences |
Personality |
Philosophy |
Social |
Methods |
Statistics |
Clinical |
Educational |
Industrial |
Professional items |
World psychology |
Statistics: Scientific method · Research methods · Experimental design · Undergraduate statistics courses · Statistical tests · Game theory · Decision theory
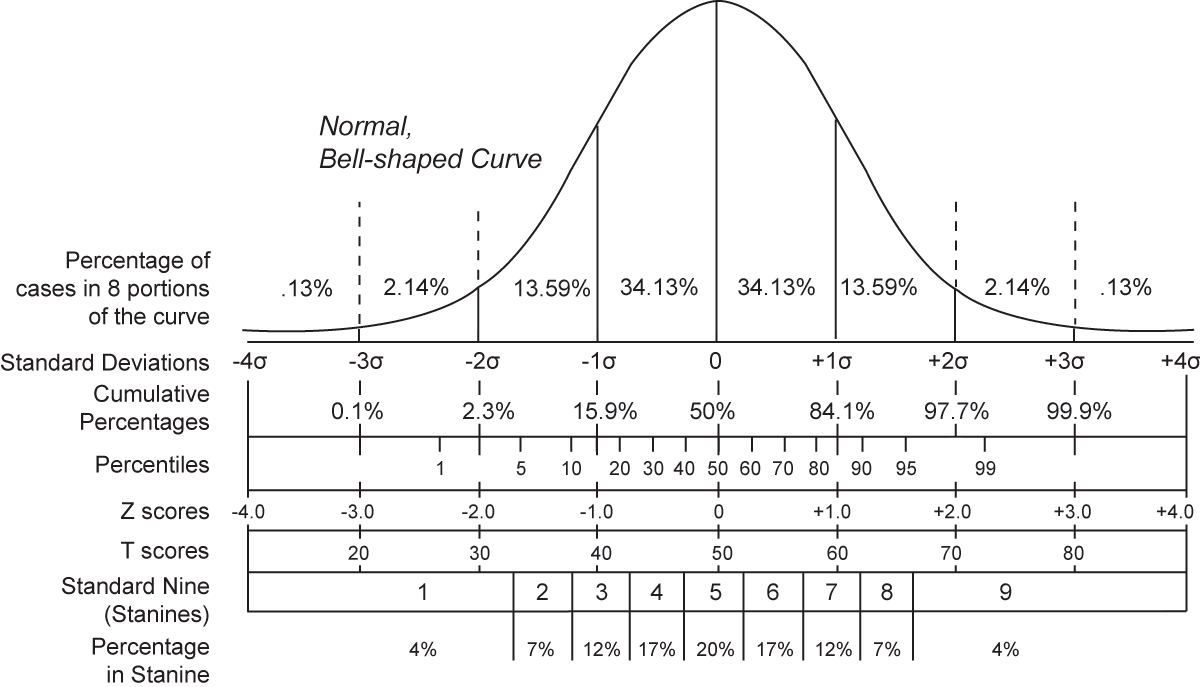
A graph of a bell curve in a normal distribution showing statistics used in educational assessment, comparing various grading methods. Shown are standard deviations, cumulative percentages, percentile equivalents, Z-scores, T-scores, standard nine, and percent in stanine.
Statistics is a mathematical science pertaining to the collection, analysis, interpretation, and presentation of data. It is applicable to a wide variety of academic disciplines, from the physical and social sciences to the humanities; it is also used for making informed decisions in all areas of business and government.
Statistical methods can be used to summarize or describe a collection of data; this is called descriptive statistics. In addition, patterns in the data may be modeled in a way that accounts for randomness and uncertainty in the observations, to draw inferences about the process or population being studied; this is called inferential statistics. Both descriptive and inferential statistics can be considered part of applied statistics. There is also a discipline of mathematical statistics, which is concerned with the theoretical basis of the subject.
The word statistics is also the plural of statistic (singular), which refers to the result of applying a statistical algorithm to a set of data, as in employment statistics, accident statistics, etc.
Historical overview
Science of state
The word statistics ultimately derives from the modern Latin term statisticum collegium ("council of state") and the Italian word statista ("statesman" or "politician"). The German] Statistik, first introduced by Gottfried Achenwall (1749), originally designated the analysis of data about the state, signifying the "science of state" (then called political arithmetic in English). It acquired the meaning of the collection and classification of data generally in the early 19th century. It was introduced into English by Sir John Sinclair.
Thus, the original principal purpose of Statistik was data to be used by governmental and (often centralized) administrative bodies. The collection of data about states and localities continues, largely through national and international statistical services. In particular, censuses provide regular information about the population.
During the 20th century, the creation of precise instruments for public health concerns (epidemiology, biostatistics, etc.) and economic and social purposes (unemployment rate, econometry, etc.) necessitated substantial advances in statistical practices. This became a necessity for Western welfare states developed after World War I which had to develop a specific knowledge of their "population". Philosophers such as Michel Foucault have argued that this constituted a form of "biopower", a term which has since been used by many other authors.
Origins in probability
The mathematical methods of statistics emerged from probability theory, which can be dated to the correspondence of Pierre de Fermat and Blaise Pascal (1654). Christiaan Huygens (1657) gave the earliest known scientific treatment of the subject. Jakob Bernoulli's Ars Conjectandi (posthumous, 1713) and Abraham de Moivre's Doctrine of Chances (1718) treated the subject as a branch of mathematics. [1]
The theory of errors may be traced back to Roger Cotes's Opera Miscellanea (posthumous, 1722), but a memoir prepared by Thomas Simpson in 1755 (printed 1756) first applied the theory to the discussion of errors of observation. The reprint (1757) of this memoir lays down the axioms that positive and negative errors are equally probable, and that there are certain assignable limits within which all errors may be supposed to fall; continuous errors are discussed and a probability curve is given.
Pierre-Simon Laplace (1774) made the first attempt to deduce a rule for the combination of observations from the principles of the theory of probabilities. He represented the law of probability of errors by a curve. He deduced a formula for the mean of three observations. He also gave (1781) a formula for the law of facility of error (a term due to Lagrange, 1774), but one which led to unmanageable equations. Daniel Bernoulli (1778) introduced the principle of the maximum product of the probabilities of a system of concurrent errors.
The method of least squares, which was used to minimize errors in data measurement, is due to Adrien-Marie Legendre (1805), who introduced it in his Nouvelles méthodes pour la détermination des orbites des comètes (New Methods for Determining the Orbits of Comets). In ignorance of Legendre's contribution, an Irish-American writer, Robert Adrain, editor of "The Analyst" (1808), first deduced the law of facility of error. He gave two proofs, the second being essentially the same as John Herschel's (1850). Carl Friedrich Gauss gave the first proof which seems to have been known in Europe (the third after Adrain's) in 1809. Further proofs were given by Laplace (1810, 1812), Gauss (1823), James Ivory (1825, 1826), Hagen (1837), Friedrich Bessel(1838), W. F. Donkin (1844, 1856), and Morgan Crofton (1870).
Other contributors were Ellis (1844), Augustus De Morgan (1864), Glaisher (1872), and Giovanni Schiaparelli (1875). Peters's (1856) formula for , the probable error of a single observation, is well known.

In the nineteenth century authors on the general theory included Laplace, Sylvestre Lacroix(1816), Littrow (1833), Richard Dedekind (1860), Helmert (1872), Hermann Laurent(1873), Liagre, Didion, and Karl Pearson. Augustus De Morgan and George Boole improved the exposition of the theory.
Adolphe Quetelet (1796-1874), another important founder of statistics, introduced the notion of the "average man" (l'homme moyen) as a means of understanding complex social phenomena such as crime rates, marriage rates or suicide rates.
Statistics today
Today the use of statistics has broadened far beyond its origins as a service to a state or government. Individuals and organizations use statistics to understand data and make informed decisions throughout the natural and social sciences, medicine, business, and other areas.
Statistics is generally regarded not as a subfield of mathematics but as a distinct, albeit allied, field. Many universities maintain separate mathematics and statistics departments. Statistics is also taught in departments as diverse as psychology, education, and public health.
Important contributors to statistics
- Thomas Bayes
- Pafnuty Chebyshev
- Sir David Cox
- Gertrude Cox
- W. Edwards Deming
- George Dantzig
- Sir Ronald Fisher
- Sir Francis Galton
- Carl Gauss
- William Sealey Gosset (known as "Student")
- Aleksandr Lyapunov
- Abraham De Moivre
- Florence Nightingale
- Blaise Pascal
- Karl Pearson
- Adolph Quetelet
- Walter A. Shewhart
- Charles Spearman
- John Tukey
See also list of statisticians.
Conceptual overview
In applying statistics to a scientific, industrial, or societal problem, one begins with a process or population to be studied. This might be a population of people in a country, of crystal grains in a rock, or of goods manufactured by a particular factory during a given period. It may instead be a process observed at various times; data collected about this kind of "population" constitute what is called a time series.
For practical reasons, rather than compiling data about an entire population, one usually instead studies a chosen subset of the population, called a sample. Data are collected about the sample in an observational or experimental setting. The data are then subjected to statistical analysis, which serves two related purposes: description and inference.
- Descriptive statistics can be used to summarize the data, either numerically or graphically, to describe the sample. Basic examples of numerical descriptors include the mean and standard deviation. Graphical summarizations include various kinds of charts and graphs.
- Inferential statistics is used to model patterns in the data, accounting for randomness and drawing inferences about the larger population. These inferences may take the form of answers to yes/no questions (hypothesis testing), estimates of numerical characteristics (estimation), forecasting of future observations, descriptions of association (correlation), or modeling of relationships (regression). Other modeling techniques include ANOVA, time series, and data mining.
The concept of correlation is particularly noteworthy. Statistical analysis of a data set may reveal that two variables (that is, two properties of the population under consideration) tend to vary together, as if they are connected. For example, a study of annual income and age of death among people might find that poor people tend to have shorter lives than affluent people. The two variables are said to be correlated. However, one cannot immediately infer the existence of a causal relationship between the two variables; see correlation implies causation (logical fallacy).
If the sample is representative of the population, then inferences and conclusions made from the sample can be extended to the population as a whole. A major problem lies in determining the extent to which the chosen sample is representative. Statistics offers methods to estimate and correct for randomness in the sample and in the data collection procedure, as well as methods for designing robust experiments in the first place; see experimental design.
The fundamental mathematical concept employed in understanding such randomness is probability. Mathematical statistics (also called statistical theory) is the branch of applied mathematics that uses probability theory and analysis to examine the theoretical basis of statistics.
The use of any statistical method is valid only when the system or population under consideration satisfies the basic mathematical assumptions of the method. Misuse of statistics can produce subtle but serious errors in description and interpretation — subtle in that even experienced professionals sometimes make such errors, and serious in that they may affect social policy, medical practice and the reliability of structures such as bridges and nuclear power plants.
Even when statistics is correctly applied, the results can be difficult to interpret for a non-expert. For example, the statistical significance of a trend in the data — which measures the extent to which the trend could be caused by random variation in the sample — may not agree with one's intuitive sense of its significance. The set of basic statistical skills (and skepticism) needed by people to deal with information in their everyday lives is referred to as statistical literacy.
Statistical methods
Experimental and observational studies
A common goal for a statistical research project is to investigate causality, and in particular to draw a conclusion on the effect of changes in the values of predictors or independent variables on a response or dependent variable. There are two major types of causal statistical studies, experimental studies and observational studies. In both types of studies, the effect of differences of an independent variable (or variables) on the behavior of the dependent variable are observed. The difference between the two types is in how the study is actually conducted. Each can be very effective.
An experimental study involves taking measurements of the system under study, manipulating the system, and then taking additional measurements using the same procedure to determine if the manipulation may have modified the values of the measurements. In contrast, an observational study does not involve experimental manipulation. Instead data are gathered and correlations between predictors and the response are investigated.
An example of an experimental study is the famous Hawthorne studies which attempted to test changes to the working environment at the Hawthorne plant of the Western Electric Company. The researchers were interested in whether increased illumination would increase the productivity of the assembly line workers. The researchers first measured productivity in the plant then modified the illumination in an area of the plant to see if changes in illumination would affect productivity. Due to errors in experimental procedures, specifically the lack of a control group and blindedness, the researchers were unable to do what they planned, in what is known as the Hawthorne effect.
An example of an observational study is a study which explores the correlation between smoking and lung cancer. This type of study typically uses a survey to collect observations about the area of interest and then perform statistical analysis. In this case, the researchers would collect observations of both smokers and non-smokers and then look at the number of cases of lung cancer in each group.
The basic steps for an experiment are to:
- plan the research including determining information sources, research subject selection, and ethical considerations for the proposed research and method,
- design the experiment concentrating on the system model and the interaction of independent and dependent variables,
- summarize a collection of observations to feature their commonality by suppressing details (descriptive statistics),
- reach consensus about what the observations tell us about the world we observe (statistical inference),
- document and present the results of the study.
Levels of measurement
There are four types of measurements or measurement scales used in statistics. The four types or levels of measurement (nominal, ordinal, interval, and ratio) have different degrees of usefulness in statistical research. Ratio measurements, where both a zero value and distances between different measurements are defined, provide the greatest flexibility in statistical methods that can be used for analysing the data. Interval measurements have meaningful distances between measurements but no meaningful zero value (such as IQ measurements or temperature measurements in degrees Celsius). Ordinal measurements have imprecise differences between consecutive values but a meaningful order to those values. Nominal measurements have no meaningful rank order among values.
Statistical techniques
Some well known statistical tests and procedures for research observations are:
- Student's t-test
- chi-square
- analysis of variance (ANOVA)
- Mann-Whitney U
- regression analysis
- correlation
- Fisher's Least Significant Difference test
Specialized disciplines
Some sciences use applied statistics so extensively that they have specialized terminology. These disciplines include:
- Biostatistics
- Data mining (applying statistics and pattern recognition to discover knowledge from data)
- Statistical physics
- Demography
- Psychological statistics
- Social statistics (for all the social sciences)
- Statistical literacy
- Statistical surveys
Software
The rapid and sustained increases in computing power starting from the second half of the 20th century have had a substantial impact on the practice of statistical science. Early statistical models were almost always from the class of linear models, but powerful computers, coupled with suitable numerical algorithms, caused a resurgence of interest in nonlinear models (especially neural networks and decision trees) and the creation of new types, such as generalised linear models and multilevel models.
The computer revolution has implications for the future of statistics, with a new emphasis on "experimental" and "empirical" statistics and a large number of statistical packages.
Criticism
There is a general perception that statistical knowledge is all-too-frequently intentionally misused, by finding ways to interpret the data that are favorable to the presenter. (A famous quote, variously attributed, but thought to be from Benjamin Disraeli [2] is: "There are three types of lies - lies, damn lies, and statistics.") Indeed, the well-known book How to Lie with Statistics by Darrell Huff discusses many cases of deceptive uses of statistics, focusing on misleading graphs. By choosing (or rejecting, or modifying) a certain sample, results can be manipulated; throwing out outliers is one means of doing so. This may be the result of outright fraud or of subtle and unintentional bias on the part of the researcher.
As further studies contradict previously announced results, people may become wary of trusting such studies. One might read a study that says (for example) "do X to reduce high blood pressure", followed by a study that says "doing X does not affect high blood pressure", followed by a study that says "doing X actually worsens high blood pressure". Often the studies were conducted on different groups with different protocols, or a small-sample study that promised intriguing results has not held up to further scrutiny in a large-sample study. However, many readers may not have noticed these distinctions, or the media may have oversimplified this vital contextual information, and the public's distrust of statistics is thereby increased.
However, deeper criticisms come from the fact that the hypothesis testing approach, widely used and in many cases required by law or regulation, forces one hypothesis to be 'favored' (the null hypothesis), and can also seem to exaggerate the importance of minor differences in large studies. A difference that is highly statistically significant can still be of no practical significance.
In the fields of psychology and medicine, especially with regard to the approval of new drug treatments by the Food and Drug Administration, criticism of the hypothesis testing approach has increased in recent years. One response has been a greater emphasis on the p-value over simply reporting whether or not a hypothesis was rejected at the given level of significance . Here again, however, this summarises the evidence for an effect but not the size of the effect. One increasingly common approach is to report confidence intervals instead, since these indicate both the size of the effect and the uncertainty surrounding it. This aids in interpreting the results, as the confidence interval for a given simultaneously indicates both statistical significance and effect size.

{kind=link}
Note that both the p-value and confidence interval approaches are based on the same fundamental calculations as those entering into the corresponding hypothesis test. The results are stated in a more detailed format, rather than the yes-or-no finality of the hypothesis test, but use the same underlying statistical methodology.
A truly different approach is to use Bayesian methods; see Bayesian inference. This approach has been criticized as well, however. The strong desire to see good drugs approved and harmful or useless ones restricted remain conflicting tensions (Type I and Type II errors in the language of hypothesis testing).
In his book Statistics As Principled Argument, Robert P. Abelson makes the case that statistics serves as a standardized means of settling arguments between scientists who could otherwise each argue the merits of their own cases ad infinitum. Statistics is, in this view, a form of rhetoric. This can be viewed as a positive or a negative, but as with any means of settling a dispute, statistical methods can succeed only so long as both sides accept the approach and agree on the particular method to be used.
See also
- Analysis of variance (ANOVA)
- CHAID
- Confidence interval
- Correlation implies causation
- Data
- Data mining
- Extreme value theory
- Forecasting
- Instrumental variables estimation
- List of academic statistical associations
- List of publications in statistics
- List of statistical topics
- List of statisticians
- Machine learning
- Multivariate statistics
- Prediction interval
- Predictive analytics
- Regression analysis
- Resampling (statistics)
- Statistical phenomena
- Statistician
- Structural equation modeling
- Trend estimation
- Scientific visualization
References & Bibliography
Notes
- ↑ See Ian Hacking's The Emergence of Probability for a history of the early development of the very concept of mathematical probability.
- ↑ cf. "Damned Lies and Statistics: Untangling Numbers from the Media, Politicians, and Activists" by Joel Best. Professor Best attributes it to Disraeli, rather than Mark Twain or others.
Bibliography
- Desrosières, Alain (2004). The Politics of Large Numbers: A History of Statistical Reasoning, Trans. Camille Naish, Harvard University Press. ISBN 0-674-68932-1.
- Lindley, D.V. (1985). Making Decisions, 2nd ed., John Wiley & Sons. ISBN 0-471-90808-8.
- Hacking, Ian (1990). The Taming of Chance, Cambridge University Press. ISBN 0-521-38884-8.
- Stigler, Stephen M. (1990). The History of Statistics: The Measurement of Uncertainty before 1900, Belknap Press/Harvard University Press. ISBN 0-674-40341-X.
- Tijms, Henk (2004). Understanding Probability: Chance Rules in Everyday life, Cambridge University Press. ISBN 0-521-83329-9.
- Best, Joel (2001). Damned Lies and Statistics: Untangling Numbers from the Media, Politicians, and Activists, University of California Press. ISBN 0-520-21978-3.
- Foster,J. Barkus,E. and Yavorsky,C. (2005).Understanding and Using Advanced Statistics: A Practical Guide for Students. London, Sage. ISBN 141290014X
- Parker,Ian (2005). Qualitative Psychology: Introducing Radical Research. Buckingham: Open University Press.ISBN: 0-335-21349-9
External links
General sites and organizations
- Statlib: Data, Software and News from the Statistics Community (Carnegie Mellon)
- International Statistical Institute
- The Probability Web
- StatSci.org: Statistical Science Web
- Statistics Glossary - and other teaching and learning resources
Link collections
- Materials for the History of Statistics (Univ. of York)
- Statistics resources and calculators (Xycoon)
- StatPages.net (statistical calculations, free software, etc.)
- Bioethics Resources on the Web from the U.S. National Institute of Health (links to tutorials, case studies, and on-line courses)
Online courses and textbooks
- A variety of class notes and educational materials on probability and statistics
- Electronic Statistics Textbook (StatSoft,Inc.)
- HyperStat Online: An Introductory Statistics Textbook and Online Tutorial for Help in Statistics Courses (David Lane)
- Primer in Statistics Reference (MiC Quality) (PDF)
- Statistics: Lecture Notes (from a professor at Richland Community College)
- Statnotes: Topics in Multivariate Analysis, by G. David Garson
- Teach/Me Data Analysis (a Springer-Verlag book)
Other resources
- ANOVA
- Disputes in statistical analyses a single-page review (PDF).
- Reality Clock - Statistics that reflect the issues facing society and the world today.
- Resampling: A Marriage of Computers and Statistics (ERIC Digests)
- Resources for Teaching and Learning about Probability and Statistics (ERIC Digests)
- Software Reports by Statistical Software Newsletter
- Statistical resources archive at UCLA
- Statistics in Sports (Section of the ASA)
| This page uses Creative Commons Licensed content from Wikipedia (view authors). |